The choice between quantitative and qualitative approaches is a long standing divide in sociology. Vincent Traag and Thomas Franssen, sociologists affiliated to CWTS, use scientometric analysis to study this divide and to see what is left of it today.
Since the dawn of sociology it has been a divisive issue: quantitative versus qualitative. The very word sociology (from French sociologie) was suggested by one of the founding scholars, Auguste Comte, as an alternative to social physics (again from French physique sociale) a term appropriated by Adolphe Quetelet, who used it to describe his statistical research. Until the 1920s, objects were deemed to be of either a quantitative or a qualitative nature. This dichotomy changed after the 1920s due to a steady rise of statistical methods in sociology. In contemporary sociology, both approaches are increasingly used to study the same general topics. However, as we will show below, the divide never fully subsided. Moreover, we find that research topics are intimately tied to their methods. The universe of quantitative sociology consists of terms like "survey", "data" and "scale" but also of "socioeconomic status", "women", "men" and "career". The universe of qualitative sociology consists of terms such as "discourse", "practice" and "meaning" but also of "power", "identity" and "masculinity".
In scientometrics, the divide between qualitative and quantitative approaches is equally apparent. Citations can be counted (although not without considerable effort). These citation counts in turn feed more complex indicators, correcting for example for field differences in citation cultures. The dynamics of citation counts can be analysed, seeing the ebb and flow of scholarly attention. In short, the quantitative part is well represented. But what citations say about scientific quality, how they bias perceived quality, and how citation analysis in turn affects scholarly practices, cannot be answered by figures alone. In addition, interpreting citation metrics without knowing the wider substantive context may lead to distorted conclusions. What publications are analysed? What is their topic, and how do different topics relate to one another?
Interestingly, this lends itself to an analysis that is a combination of both a quantitative and a qualitative approach. At CWTS, one of the tools at our disposal for trying to make sense of large sets of publications is a term map. The idea is that we extract the most relevant terms from the titles and abstracts of the publications we are studying. Those terms emerge from the titles and abstracts themselves, uncovered by sophisticated text mining techniques, and are not in any way predetermined. We visualise and cluster these terms in such a way that frequently co-occurring terms are positioned relatively close to each other, and are part of the same cluster. These techniques are implemented in the freely available VOSviewer, we provide some more (technical) details below. Although such a visualisation is based on text mining large amounts of textual data—a rather quantitative approach—the resulting maps require expert, substantive domain knowledge to understand and interpret them—a qualitative approach.
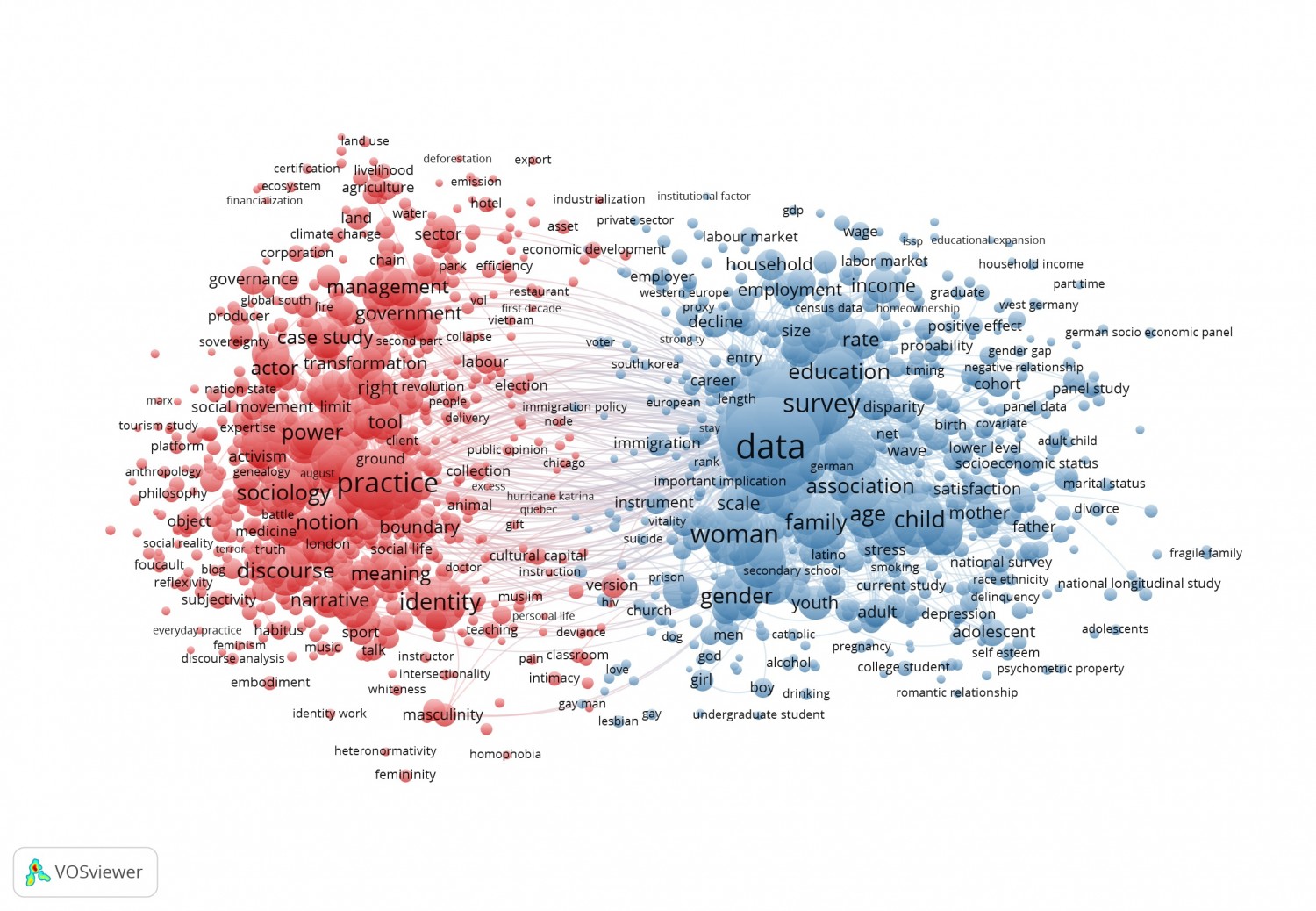 Figure 1. Map of the field of sociology 2010–2015. Terms are coloured according to the cluster. The map reveals the quantitative-qualitative divide. Click here to open an interactive map in the VOSviewer.
Figure 1. Map of the field of sociology 2010–2015. Terms are coloured according to the cluster. The map reveals the quantitative-qualitative divide. Click here to open an interactive map in the VOSviewer.
When we apply these techniques to all articles published in journals classified as sociology in the Web of Science in 2010-2015, we see an interesting pattern appear. We would expect a field of science to be subdivided in topics: words that frequently co-occur together tend to concern some common topic. In sociology, the map reveals quite a different division, namely between quantitative and qualitative approaches. It is rather surprising to see this phenomenon dominate the division, rather than say, topics such as inequality, social movements or organisations. Of course, such topics are also included in the map, but they seem to be part of the broader divide between quantitative and qualitative. For example, many publications on social movements tend to be case based and involve discourse analysis. Similarly, questions of identity tend to be studied using qualitative, ethnographic methods. On the other hand, topics related to employment, income and education (presumably dealing with inequality) employ more frequently a quantitative methodology. It might be interesting to see these topics studied from the other method: identity from a quantitative perspective and employment, income and education from a qualitative perspective.
There are some interesting crossovers from quantitative to qualitative that show how the same general topic is approached differently in the two methods. Differences between "male" and "female" seem to be studied more in a quantitative setting. But the topic is also studied qualitatively, around issues such as identity and sexuality, where we see terms such as "masculinity" pop-up. Religious matters are similarly studied from both perspectives. On the one hand, this is a typical control variable in quantitative studies (going to church for example). But religiosity is of course also deeply ingrained in questions of identity and meaning. In issues of development, globalization and climate change, the qualitative focus is not on identity and meaning, but on communities and villages, especially in the developing world. The quantitative approach is focused more on redistribution, economic growth and cross national comparison. Finally, some other methodologies such as social network analysis and rational choice theory also straddle the quantitative-qualitative boundary. For rational choice theory this seems counter intuitive, but perhaps rational choice theory is as frequently critiqued by qualitative papers as it is employed by quantitative papers. More generally speaking, term maps provide only a rough overview of a field based on co-occurrence, and the context of co-occurrence is not considered. Whether a term co-occurs because it is critiqued or employed is therefore not clear. We should thus refrain from reading too much into such maps.
Perhaps we can conclude from this small foray into the quantitative-qualitative divide that particular research topics are often confined to one method. A qualitative approach yields a richer, thicker description, and embeds an analysis in a wider context. At the same time, it may trigger questions that require a more quantitative answer, which in turn may require again a more qualitative analysis. We may thus continuously switch between qualitative and quantitative methods. Rather than trying to integrate the two, which is for example promoted under the heading of mixed methods, we should perhaps mostly keep challenging both views from the other perspective. We should not be blind to the challenges posed by the other perspective, but accept that the other perspective can supplement and nuance our conclusions, rather than invalidate them. Fortunately, when looking at the distribution of publications in journals, some of the more general journals, such as American Sociological Review and American Journal of Sociology do include publications from both perspectives (although the quantitative perspective seems more present). More specialised journals, such as Cultural Sociology and Social Forces, mainly focus on respectively qualitative and quantitative research. At least, there are some common fora for discussion, but there is room for improvement.
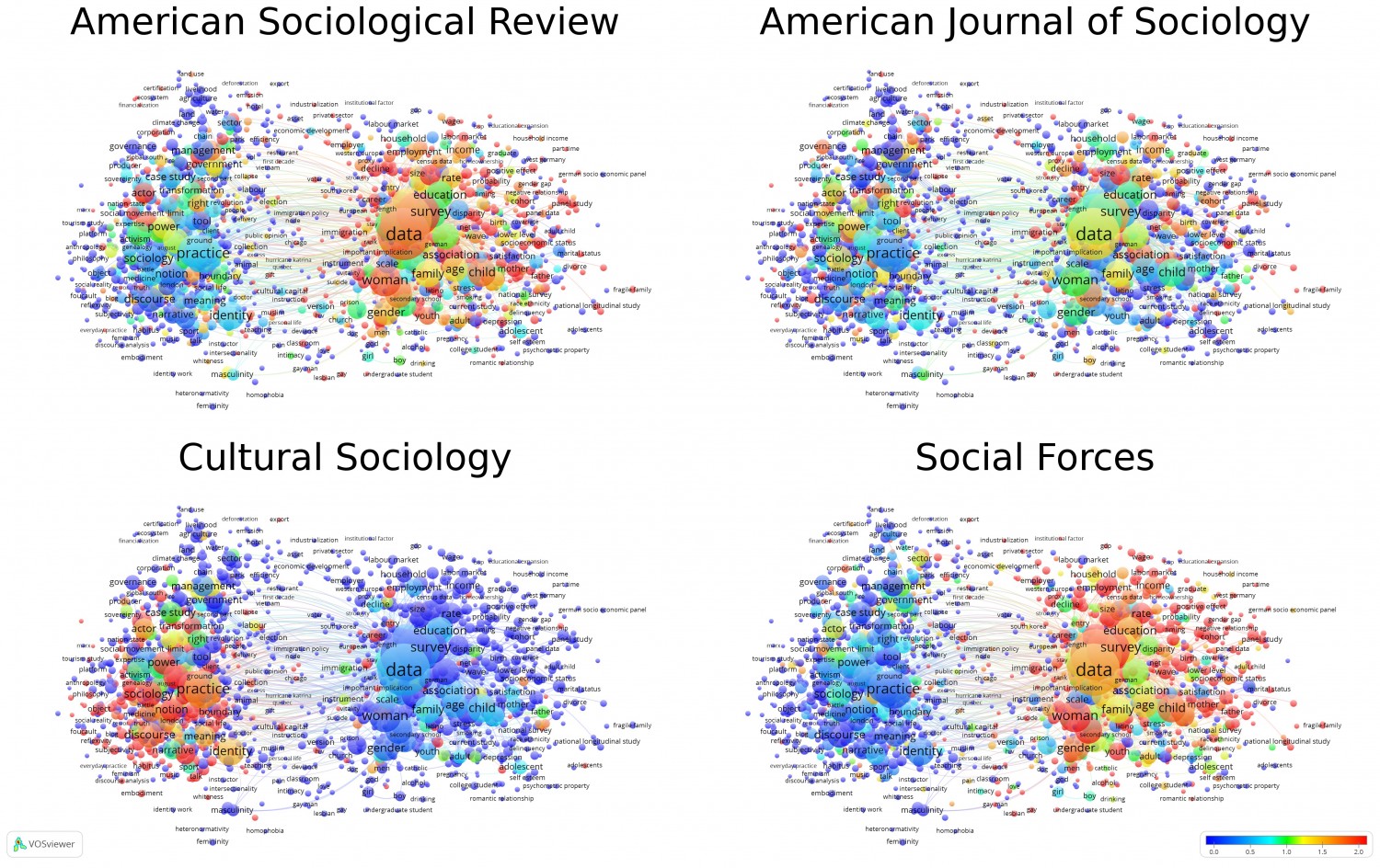
Figure 2. Maps showing the relative frequency of terms in journals. Blue represents few occurrences while red represents more frequent occurrences. Click here to open interactive maps in the VOSviewer.
Methods & References
Methods
We collected all articles published in journals that belong to the subject category of Sociology in the Web of Science, published between 2010-2015. In total, there are 14,613 articles published in that period in 146 different journals. We input the titles and abstracts into the VOSviewer, which identifies terms from the text (technically known as noun phrases) using a natural language processing algorithm. We then exclude terms that occur less than 20 times in this corpus, which results in 2450 terms. Using these terms, the VOSviewer calculates a so-called relevance score to exclude generic terms. For example, a term such as "conclusion" appears frequently, but co-occurs with almost any other term. Such generic terms are thus excluded based on a low relevance score. We select the 60% most relevant terms that remain, which results in 1470 terms. See Van Eck et al. (2011) for more technical details on how these terms are extracted and how relevance scores are calculated, and see Van Eck & Waltman (2010) for a more general overview of the VOSviewer. The overall quantitative-qualitative divide seems quite robust with respect to slightly different choices of parameters. For example, using a cut-off of 15 occurrences and selecting the 1500 most relevant terms reveals a nearly identical map, and so does a cut-off of 25 occurrences and selecting the top 1000 most relevant terms.
The terms are visualised using a method that tries to position frequently co-occurring terms close to each other. For those with some technical background, the technique resembles a weighted variant of multidimensional scaling. More information can be found in Van Eck et al. (2010). Finally, the terms are clustered using the same mathematical framework as used for the visualisation, as explained in Waltman, Van Eck & Noyons (2010). The clustering technique resembles modularity, a well-known method for detecting communities in networks, but there are some subtle differences. In particular, different granularities of clustering can be found, and we need to set some resolution parameter. The default setting in the VOSviewer is 1, which still identifies some subtopics in the field of sociology, such as gender issues. The coarser division between quantitative-qualitative is revealed at a resolution somewhere in the range of about 0.55-0.85. Finally, we normalise the frequency of a term in a journal so that the average is equal to 1, to arrive at comparable scales for the colours (we visualize on a common scale of 0-2).
References
Van Eck, N. J., & Waltman, L. (2010). Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics, 84(2), 523–538.
Van Eck, N.J., Waltman, L., Dekker, R., & Van den Berg, J. (2010). A comparison of two techniques for bibliometric mapping: Multidimensional scaling and VOS. Journal of the American Society for Information Science and Technology, 61(12), 2405-2416.
Van Eck, N.J., & Waltman, L. (2011). Text mining and visualization using VOSviewer. ISSI Newsletter, 7(3), 50-54.
Waltman, L., van Eck, N. J., & Noyons, E. C. M. (2010). A unified approach to mapping and clustering of bibliometric networks. Journal of Informetrics, 4(4), 629–635.

