In discussions about the use of citation-based indicators (‘metrics’) in research evaluations, the degree to which these indicators yield results that are in agreement with the outcomes of peer review exercises plays a key role. Unfortunately, there is a lack of consensus on how agreement between metrics and peer review can best be analysed. As a consequence, different studies take different approaches, obtain different results, and sometimes draw completely opposite conclusions.
This is clearly visible in discussions about the use of metrics in the Research Excellence Framework (REF) in the UK, where some studies report an almost perfect correlation between metrics and peer review while other studies, most notably the influential Metric Tide report, suggest that metrics and peer review are only weakly correlated. Based on a paper that we published last week, we propose four principles for studying agreement between metrics and peer review in a systematic manner. Below, we illustrate each of these principles with concrete examples obtained from our analysis of the UK REF.
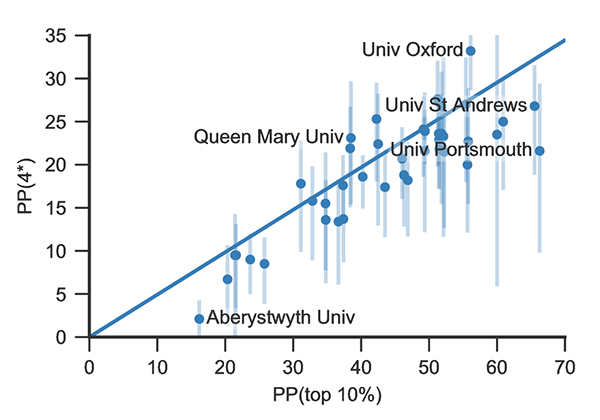
1. Choose the proper level of aggregation
The agreement between metrics and peer review depends on the level of aggregation. The Metric Tide report analysed agreement between metrics and peer review at the level of individual publications. However, this is not the appropriate level of aggregation in the context of the REF. The goal of the REF is not to evaluate individual publications but to evaluate institutions. Even though metrics and peer review are only weakly correlated at the individual publication level, they may still be quite strongly correlated at the institutional level; the errors may ‘cancel out’. Indeed, correlations turn out to be substantially higher at the institutional level (often around 0.7) than at the publication level (always below 0.4).
2. Distinguish between size-dependent and size-independent perspectives
The REF has multiple objectives: it aims to provide a reputational yardstick and a basis for distributing funding. A reputational yardstick is usually related to the average scientific quality of the publications of an institution. As such, it is size-independent: it does not depend on the size of an institution. On the other hand, in the REF, funding is allocated based on the total scientific quality of the publications of an institution, which means that funding is size-dependent: institutions with more output or staff generally receive more funding. Given the multiple objectives of the REF, agreement between metrics and peer review in the REF should be analysed from both a size-dependent and a size-independent perspective.
Importantly, correlations between metrics and peer review tend to be much higher from a size-dependent perspective than from a size-independent perspective. This is because in the size-dependent perspective metrics and peer review share a common factor, namely the size of an institution. Size-dependent correlations can be very high even when the corresponding size-independent correlations are low. For example, in the field of mathematics in the REF, the size-dependent correlation between metrics and peer review equals 0.96, whereas the size-independent correlation equals only 0.39.
3. Use an appropriate measure of agreement
Correlation coefficients provide only limited insight into agreement between metrics and peer review, and especially in size-dependent analyses correlation coefficients could lead to misleading conclusions. Alternative measures of agreement should therefore be considered, for example the median absolute difference and the median absolute percentage difference.
The median absolute difference gives an indication of the absolute increase or decrease that can be expected when switching from peer review to metrics. We consider this measure to be especially informative when taking a size-independent perspective. On average, about 30% of the publications in the UK REF are marked as “world-leading”. In fields such as physics and clinical medicine, we find a median absolute difference of about 3 percentage points for the percentage of “world-leading” publications. Hence, in these fields, switching from peer review to metrics will typically lead to an increase or decrease in the percentage of “world-leading” publications of an institution by about 3 percentage points.
Taking a size-dependent perspective and focusing on the funding received by institutions, we consider the median absolute percentage difference to be an insightful measure of agreement. In physics and clinical medicine, the median absolute percentage difference between metrics and peer review in the REF is about 15%. This essentially means that in these fields the funding allocated to an institution will typically increase or decrease by about 15% when switching from peer review to metrics.
4. Acknowledge uncertainty in peer review
Regardless of the level of aggregation, the perspective (i.e. size-dependent or size-independent), and the measure of agreement, it is crucial to acknowledge that peer review is subject to uncertainty. Hypothetically, if the REF peer review had been carried out twice, based on the same publications but with different experts, the outcomes would not have been the same. Comparing the outcomes of two independent peer review exercises provides an indication of the internal agreement of peer review. This provides a sensible baseline with which to compare the agreement between metrics and peer review. If agreement between metrics and peer review is similar to internal peer review agreement, metrics and peer review yield essentially indistinguishable results.
Unfortunately, there are no empirical measurements of peer review uncertainty in the REF. In our paper, we therefore study peer review uncertainty based on a simple mathematical model. We recommend that peer review uncertainty should be measured empirically in the next edition of the REF in 2021.
Our model of peer review uncertainty suggests that in some fields, in particular in physics, clinical medicine, and public health, agreement between metrics and peer review is quite close to internal peer review agreement. In these fields, differences between metrics and peer review seem to be of a similar magnitude as differences between two peer review exercises, from both a reputational (size-independent) and a funding (size-dependent) perspective.
Conclusion
A large number of scientometric studies have analysed agreement between metrics and peer review. Many of these studies take one specific perspective, often without a clear motivation, leading to apparent inconsistencies in the literature. To develop a systematic understanding of agreement between metrics and peer review, we consider it essential to take into account the four principles presented above.
Finally, we emphasize that, even if metrics are found to agree well with peer review, there may be other arguments against replacing peer review by metrics, such as arguments related to goal displacement. The various arguments should be carefully weighed in discussions about the use of metrics as an alternative to peer review. We therefore do not suggest that metrics should replace peer review in the REF. However, in some REF fields, the argument that metrics should not be used because of their low agreement with peer review does not stand up to closer scrutiny.

