Introduction
An exciting development in the field of quantitative science studies is the use of algorithmic clustering approaches to construct article-level classifications based on citation networks. Until recently, most classifications were based on categorizing journals rather than individual articles. This is understandable given the substantial challenges of classifying millions of articles. At CWTS, we now routinely work with article-level classifications. We have dedicated quite some time developing clustering algorithms for creating these classifications. These algorithms have an impact beyond our own research field and are of interest to many network scientists.
You may be surprised to learn that one the most famous clustering algorithms—commonly known as the Louvain algorithm—actually has a major flaw: the clusters it finds can be arbitrarily badly connected. For instance, the Louvain algorithm may group articles together in a cluster even though some of the articles have no citation links with the other articles in the cluster. We here briefly report on a new algorithm that we have developed, which we call the Leiden algorithm. This algorithm guarantees to find well-connected clusters. Even better, it does so much faster than the Louvain algorithm!
Louvain algorithm
The Louvain algorithm is a simple and elegant algorithm that is more efficient than many other network clustering algorithms. When it was introduced in 2008, it was applied to a huge network of more than one hundred million nodes and one billion links. It ranked among the best performing clustering algorithms in comparative studies in 2009 and 2016. The Louvain algorithm searches for high-quality clusters by moving individual nodes—for instance individual articles in a citation network—from one cluster to another in such a way that the quality of the clusters is improved as much as possible. When clusters cannot be improved further by moving individual nodes, the Louvain algorithm does something ingenious: it aggregates the network, so that each cluster in the original network becomes a node in the aggregated network. In the aggregated network, the algorithm then starts to move individual nodes from one cluster to another. By repeating the node movement and aggregation, the Louvain algorithm is able to find high-quality clusters in a short time. Unfortunately, however, this approach also leads to an important flaw, which seems to have gone unnoticed during the past decade.
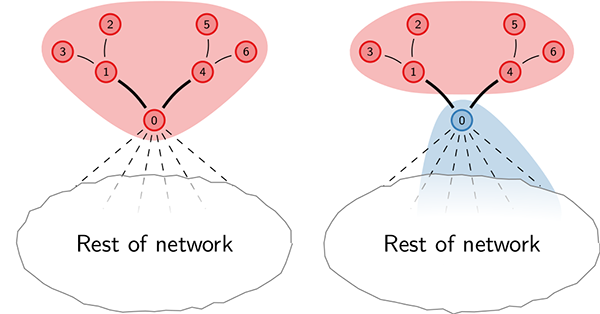
Sometimes, a node functions as a middle man or a bridge for the rest of its cluster. Without that crucial node, the cluster would not be connected anymore. Since the Louvain algorithm keeps moving nodes from one cluster to another, at some point it may move the crucial node to a different cluster, thereby breaking the connectivity of the original cluster. Perhaps surprisingly, the Louvain algorithm cannot fix this shattered connectivity. The complete breaking of connectivity is the worst thing that can happen to a cluster. It is the most extreme example of a more general problem of the Louvain algorithm: the algorithm can produce clusters that are badly connected and that should have been split up into multiple clusters.
Leiden algorithm
We fix this problem of the Louvain algorithm in our new Leiden algorithm. Similarly to the Smart Local Moving algorithm that was previously developed at CWTS, the Leiden algorithm is able to split clusters instead of only merging them, as is done by the Louvain algorithm. By splitting clusters in a specific way, the Leiden algorithm guarantees that clusters are well-connected. Moreover, the algorithm guarantees more than this: if we run the algorithm repeatedly, we eventually obtain clusters that are subset optimal. This means that it is impossible to improve the quality of the clusters by moving one or more nodes from one cluster to another. This is a strong property of the Leiden algorithm. It states that the clusters it finds are not too far from optimal. Finally, rather than continuously checking for all nodes in a network whether they can be moved to a different cluster, as is done in the Louvain algorithm, the Leiden algorithm performs this check only for so-called unstable nodes. As a result, the Leiden algorithm does not only find higher quality clusters than the Louvain algorithm, it also does so in much less time.
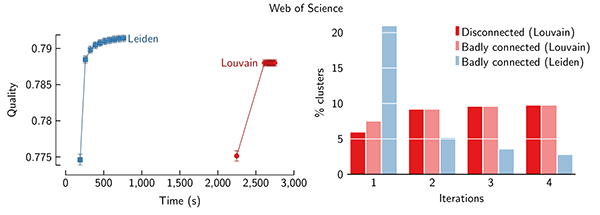
At CWTS, we use the Leiden algorithm to cluster large citation networks. The Louvain algorithm needs more than half an hour to find clusters in a network of about 10 million articles and 200 million citation links. The Leiden algorithm needs only a little over three minutes to cluster this network. Moreover, when run repeatedly, the Leiden algorithm easily finds higher quality clusters than the Louvain algorithm.
Try it yourself!
We expect the Leiden algorithm to prove useful not only to us at CWTS, but also to many other researchers in both quantitative science studies and network science. During the past decade, thousands of researchers have published papers in which they use the Louvain algorithm. In the future, these researchers could employ the Leiden algorithm.
Together with the paper introducing the Leiden algorithm, we have also released the Java source code of the algorithm on GitHub. We have made quite some effort to ensure that the algorithm is easy to use for everyone. For the more technically inclined, we have created technical documentation and code comments. Grab the source code, run it on your own network data, and let us know what you think of it!


